|
| Operations
on Sets and Venn Diagrams |
|
|
|
|
Operations on sets and Venn diagrams |
 Union,
intersection and difference
Union,
intersection and difference |
|
Partition
of a set |
|
|
|
|
|
|
| Operations
on Sets and Venn Diagrams |
|
There are three basic set operations:
union, intersection and difference (relative complement).
|
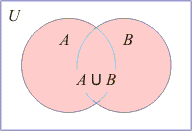
| The union of two sets A
U B
is the set that consists of all elements belonging to either
set A
or set B
(or both).
We
say that an element x
is in A
U B
if either x
is in A
or x
is in B (or
x
belongs
to both). |
| In
formal notation, A
U B
= {
x |
x Î
A or
x Î
B or
both }. |
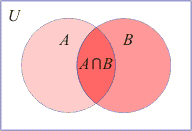
| The intersection of two sets A
∩ B
is the set of all elements that are elements of both A
and B. |
| In
formal notation, A
∩ B
= {
x |
x Î
A and
x Î
B }. |
|
|
|
|
The union and the intersections of sets A
and B
represented by Venn
Diagrams. |
|
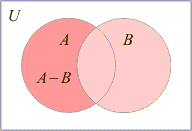
| The difference
(or the relative complement of B
in A),
denoted as A − B
(or A
\ B),
is the set of all elements
that are elements of A
but not of B.
In formal notation, A
− B
= {
x |
x Î
A and
x not
Î
of B }. |
| The
complement (or the absolute complement) of A
in U,
denoted as A'
(or Ac),
is the set of all elements of a
given universal set that are not elements of A.
In formal notation, A'
= {
x |
x Î
U
and
x not
Î
of A
}. |
|
|
|
|
The difference A
− B
and the complement A'
represented by Venn
Diagrams. |
|
|
| Example: |
Assuming
the set of natural numbers N
is the universal set given are sets, |
|
|
A = {
x Î
N
|
x <
5
},
B
= {
x Î
N
|
3
≤ x <
8 }
and
C = {
x Î
N
|
x =
2n
− 1,
n
Î N
}. |
|
Find: a) A
∩ B,
b) A
U B,
c)
A
− B,
d)
B
− A
and e)
C'. |
|
| Solution:
As A
= {
x Î
N
|
x <
5
} =
{ 1, 2, 3, 4 }, |
|
B = {
x Î
N
|
3
≤ x <
8 }
=
{ 3, 4, 5, 6, 7 } |
|
and C
= {
x Î
N
|
x =
2n
− 1,
n
Î
N
}
= {
1, 3, 5, 7, . . . } |
|
then a) A
∩ B
=
{ 3, 4 },
b) A
U B
=
{ 1, 2, 3, 4, 5, 6,
7 }, |
|
c)
A
− B
=
{ 1, 2 },
d)
B
− A
=
{ 5, 6, 7 } |
| and
e) C'
= {
x Î
N
|
x =
2n
} = {
2, 4, 6, 8, . . . }. |
|
|
| Partition
of a Set |
| A partition of a set
S is a collection of non-empty disjoint subsets of
S, whose union is
S. Two sets are said to be
disjoint if they have no elements in common. |
|
| Example: |
If
given set is {1, 2, 3, 4, 5, 6, 7} then one of its
possible partitions is { {1, 3, 7}, {2}, {4, 5}, {6} }. |
|
|
|
|
|
|
|
|
|
|
|
|
| Beginning
Algebra Contents |
|
|
 |
|
| Copyright
© 2004 - 2020, Nabla Ltd. All rights reserved. |
|
|